Objekterkennung ist ein Teilgebiet der Computer Vision, eine Wissenschaft in der Bilder und Videos auf unterschiedliche Art verarbeitet und analysiert werden, um spezifische Informationen zu extrahieren. Die spezielle Aufgabe der Objekterkennung ist es, Objekte auf Bildern oder Videos zu Erkennen und Lokalisieren. Die Gründe für den Einsatz von Objekterkennung können vielfältig sein.
- Zählen von Objekten
- Bestimmung von Größe und Position von Objekten
- Zuordnung von Objekten zu definierten Klassen
Aktuell ist ein starker Trend hinsichtlich der Forschung und Entwicklung von Software zur Erkennung von Objekten festzustellen. Berechtigterweise stellt sich hier die Frage, warum Maschinen und Computer diese Aufgaben übernehmen müssen bzw. sollen. Dazu schauen wir uns zunächst an, wo solche Software bereits verwendet wird.
Bsp. 1: Autonomes Fahren
Wer würde es nicht bevorzugen? Sich in sein Auto setzen, die Zieladresse eingeben und anschließend vollkommen autonom an das gewünschte Ziel gebracht werden. Die Grundlage des autonomen Fahrens sind Algorithmen zur Objekterkennung, die Fußgänger, Verkehrsschilder, andere Fahrzeuge und viele weitere Objekte im Straßenverkehr erkennen und daraufhin Entscheidungen treffen.
Bsp. 2: Medizinische Befunderfassung
Dank der Objekterkennung konnten in der Medizin viele Durchbrüche erzielt werden. Da sich die medizinische Diagnostik in hohem Maße auf die Untersuchung von Bildern, Scans und Fotos stützt, ist die Objekterkennung bei CT- und MRT-Scans für die Diagnose von Krankheiten äußerst nützlich geworden, zum Beispiel für die Tumorerkennung oder zum Zählen von Partikeln (z.B. Blutkörperchen) in Blutproben.
Bsp. 3 Gesichtserkennung
Das Thema Gesichtserkennung setzt sich in vielen Branchen immer stärker durch, so auch in der Reisebranche. Fluggesellschaften und Flughäfen haben inzwischen damit begonnen, die Gesichtserkennungstechnologie einzusetzen, um den Check-in und das Boarding für ihre Kunden zu verbessern. Zudem können Fluggesellschaften ihre Kosteneffizienz steigern, da sie weniger Personal für die Interaktion mit ihren Passagieren benötigen. Bei der Gesichtserkennung beim Boarding werden die Gesichter der Passagiere gescannt. Diese werden mit den in der Datenbank der Grenzkontrollbehörde gespeicherten Fotos verglichen, um die Identität der Passagiere und die Fluginformationen zu überprüfen. Die Fotos in der Datenbank können von Personalausweisen, Visa oder anderen Dokumenten stammen.
Es gibt noch viele weitere Beispiele für die Anwendung von Objekterkennung. Generell sollen diese Algorithmen den Menschen durch eine zusätzliche Sichtweise unterstützen in Aufgabenbereichen, die für den Menschen entweder zu öde, eintönig oder auch zu komplex ist. Außerdem legt die Objekterkennung den Grundstein für Automatisierung von Prozessen, bei denen eine Automatisierung zuvor nicht möglich war, wie z.B. bei einer Sichtprüfung in der Qualitätskontrolle.
Die rasanten Fortschritte im Bereich Deep Learning haben in den letzten Jahren die Entwicklung der Objekterkennung stark vorangetrieben. Dank der gestiegenen Rechenleistung von Grafikprozessoren hat sich die Leistung von Algorithmen zu Objekterkennung erheblich verbessert, was zu bedeutenden Durchbrüchen bei der Objekterkennung geführt hat. Doch worin liegt die Schwierigkeit genau warum wird eine solche hohe Rechenleistung benötigt?
Allgemein liegt die Schwierigkeit darin, den Algorithmus hinsichtlich der hohen Variation zu Generalisieren (verschiedene Posen, Beleuchtung, etc.). Es ist schwierig bis hin unmöglich durch verschiedene Regeln und Bedingungen zu beschreiben, wann genau es sich auf einem Bild um das gesuchte Objekt handelt und wo es sich befindet. Aus diesem Grund verfolgen moderne Algorithmen den Ansatz, durch Training verschiedene Muster zu erlernen und wiederzuerkennen. Trotz der beträchtlichen Fortschritte auf diesem Gebiet und der großen Fähigkeiten der Computer Vision ist die Erkennung von Objekten ein komplexer Prozess, für dessen Umsetzung unter anderem folgende Herausforderungen zu bewältigen sind:
Variation des Blickwinkels:
Das wohl größte Problem bei der Objekterkennung besteht darin, Objekte auch aus verschiedenen Blickwinkeln zu erfassen. Objekte können sich aus verschiedenen Perspektiven vollkommen voneinander unterscheiden. Während eine Kugel von allen Perspektiven betrachtet gleich aussieht, ist ein zylindrisches Objekt in der Seitenansicht ein Rechteck und in der Draufsicht ein Kreis. Ein weiteres gutes Beispiel für dieses Problem ist auf den beiden nachfolgernden Bildern dargestellt. Der Stamm eines Baumes muss nicht zwangsläufig auf Bildern immer horizontal verlaufen und im Durchmesser von unten nach oben abnehmen, so wie im linken Bild dargestellt. Das rechte Bild zeigt, dass Bäume auch aus anderen Perspektiven fotografiert werden können.


Unordentlicher oder texturreicher Hintergrund:
Eine weitere Störgröße in der Objekterkennung ist der Hintergrund. Das Problem dabei ist, dass Objekte mit dem Hintergrund verschmelzen oder verschwinden können. Ein Algorithmus, der versucht ein spezielles Buch auf dem nachfolgenden Bild zu finden, wird es schwer haben das gewünschte Objekt zu lokalisieren.

Wechselnde Beleuchtungsbedingungen:
Die Lichtverhältnisse haben einen sehr großen Einfluss auf die Wahrnehmung von Objekten. Ein Objekt sieht je nach Lichtverhältnis und Schattenwurf anders aus. Für die Objekterkennung macht es einen großen Unterschied, ob ein Objekt stark beleuchtet oder auch unterbeleuchtet ist.


Verdeckte Objekte:
Häufig werden Objekte auf Bildern teilweise von Hindernissen und anderen Objekten verdeckt. Trotzdem müssen die Algorithmen in der Lage sein, Objekte erfolgreich zu erkennen. Beispielsweise werden überwiegend nur einzelne Körperregionen von Menschen auf Bildern dargestellt.


Verformung von Objekten:
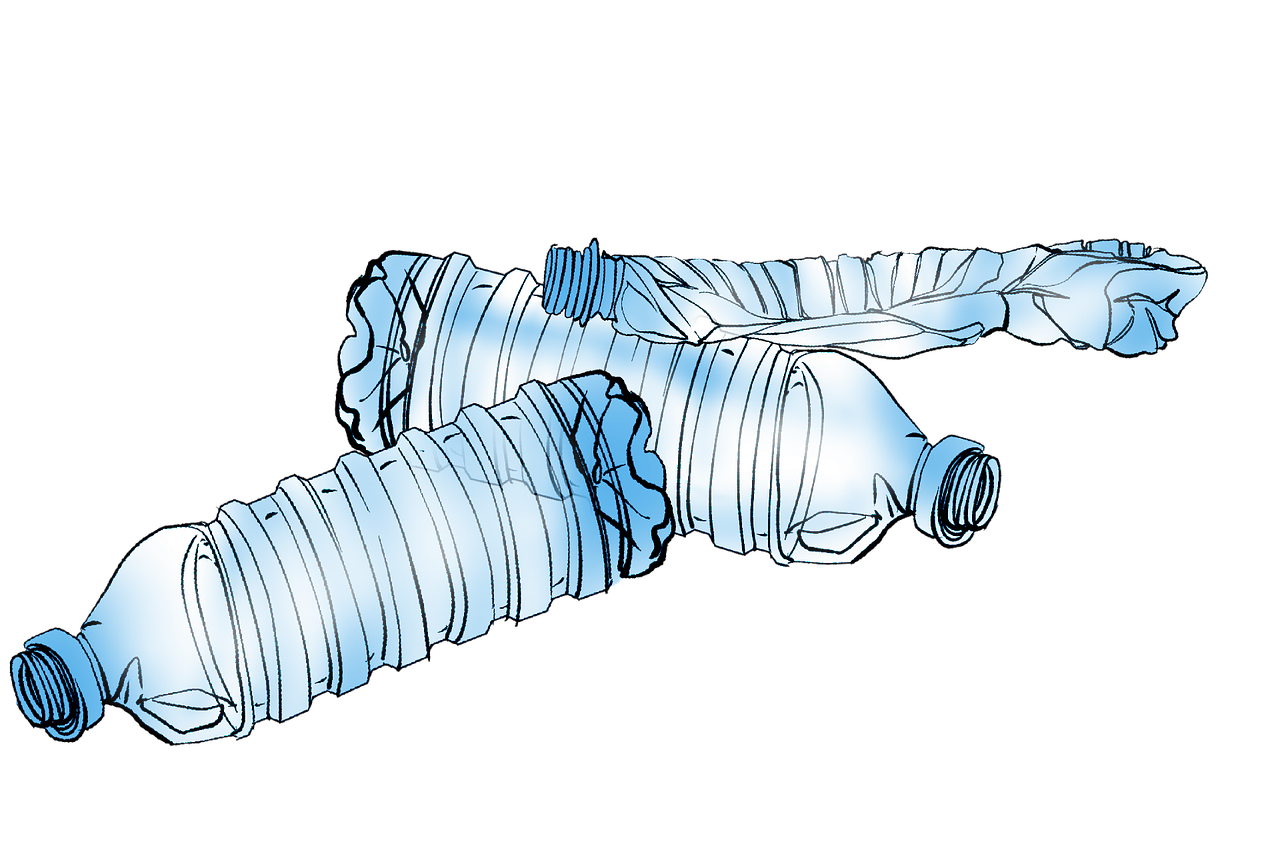
Ein weiterer Faktor, der berücksichtigt werden muss ist, dass Objekte sich auch verformen können. Ein Beispiel für solche Objekte sind PET Flaschen, wie im folgenden Bild.
Objektvielfalt:
Objektvielfalt bezeichnet das Problem in der Objekterkennung, dass ein Objekt verschiedene Varianten und Ausführungen haben kann. Eine generalisierte Lösung dafür zu finden ist nicht leicht. Trotzdem sollte ein Algorithmus in der Lage sein, beispielsweise die nachfolgenden 3 Bilder alle als Kategorie „Haus“ zu klassifizieren.



Geschwindigkeit:
Gerade bei der Verarbeitung von Videos müssen die Algorithmen zur Objekterkennung unglaublich schnell sein. Die Geschwindigkeit konkurriert dabei immer mit der Genauigkeit. Dabei kommt es immer zu einem gewissen „Trade off“, um so schnell wie nötig die Bilder zu verarbeiten mit möglichst hoher Genauigkeit. Als ideales Werkzeug zur Objekterkennung haben sich künstlich neuronale Netze bewährt. Diese neuronalen Netze werden im Vorfeld auf die spezielle Aufgabenstellung trainiert, was oftmals hohe Rechenleistung und Zeit erfordert. Sind diese Netze einmal trainiert, können Sie jedoch im Bruchteil einer Sekunde Bilder analysieren.

Auch das Kompetenzzentrum Cottbus unterstützt Unternehmen auch im Bereich der Objekterkennung sowie allgemein in der computergestützten Bildverarbeitung. Des Weiteren stellen wir kleinen Unternehmen kostenfrei Rechenleistung für das Training von Algorithmen zur Verfügung. So konnten wir bereits das Unternehmen Ourgreenery GmbH im Bereich der Objekterkennung unterstützen.
https://www.kompetenzzentrum-cottbus.digital/Projekte/Digitalisierungsprojekte/Konzeptionierung-eines-Smart-Gardens-fuer-eine-KI-Forschungs-und-Trainingsplattform.html
Dabei wurden Bilder von Pflanzen aus dem Urban Farming aufgenommen und hinsichtlich der Genießbarkeit analysiert. Die nachfolgende Tabelle vergleicht die Trainingszeiten aus dem Projekt bei unterschiedlicher Hardware. Das Yolov5s Netz wurde für das Projekt verwendet bei Trainingsbildern mit einer Auflösung von 416x416.
|
Methode
|
Zeit / Epoche
|
Zeit / 150 Epochen (ein komplettes Training)
|
|
Laptop CPU i7-7500U 2.70 GHz, 2 Kerne
|
≈ 110s
|
≈ 4.5h
|
|
Google Colab GPU NVIDIA Tesla K80
|
≈ 6s
|
≈ 0.23h
|
|
KI-Server CPU AMD EPYC 7413 24-Core Prozessor, 2.645 GHz, 24 Kerne
|
≈ 30s
|
≈ 1.25h
|
|
KI-Server GPU NVIDIA A40
|
≈ 2s
|
≈ 0.088h
|
Für Fragen rund um das Thema KI oder zu unserem KI Server bitte kontaktieren Sie:
Norman Günther
Tel.: +49 (0) 3375 508 782
Email: nguenther@th-wildau.de
Referenzen:
ZOU, Zhengxia, et al. Object detection in 20 years: A survey. arXiv preprint arXiv:1905.05055, 2019.
https://www.exposit.com/blog/computer-vision-object-detection-challenges-faced/
SÜßE, Herbert; RODNER, Erik. Bildverarbeitung und Objekterkennung. Springer Fachmedien Wiesbaden, 2014.